高性能和无忧部署的技巧
Memorystore 是开源内存数据库 Redis 和 Memcached 的完全托管实现。Memorystore 让你可以轻松地在 Google Cloud 上构建应用程序,以利用基于开源 Redis 和 Memcached 的内存存储。
今天部署在云中的许多应用程序都使用内存数据存储。一些示例用例包括缓存、实时分析、会话存储、排行榜、队列和快速数据摄取。在需要亚毫秒级延迟的情况下,Redis 和 Memcached 是这些应用程序开发人员的热门选择。本文将重点介绍 Memorystore for Redis。
尽管 Memorystore for Redis 是一项托管服务,但仍可根据你的应用程序行为和用例遵循最佳实践。以下最佳实践建议将有助于确保你的用户获得最佳体验。
用于优化内存设置的配置设置和指标
Memorystore for Redis 中最重要的设置之一是 maxmemory-gb。此设置配置 Redis 中的 maxmemory 设置,该设置指示为密钥存储保留多少内存。当达到指定的最大内存量时,将使用逐出策略。逐出策略是通过最大内存策略在 Memorystore for Redis 中设置的。默认策略是 volatile-lru,它会逐出使用生存时间 (TTL) 过期设置的最不常用的密钥。
最佳实践:
在调整 maxmemory-gb 时,你应该监控系统内存使用率 (SMUR),目标比率低于 80%。如果系统内存使用率指标超过80%,则表示实例存在内存压力。如果你不采取行动,并且你的内存使用量继续增长,你将面临因内存不足而导致实例崩溃的风险。为防止 OOM 错误,你可以考虑打开 activedefrag、降低 maxmemory-gb 以提供更多系统使用开销,或扩大实例。
由于多线程,使用 Redis 6 提高性能
Redis 6 的新特性之一是多线程 I/O 的实现。以前版本的 Redis 是单线程的,在某些情况下,这可能会导致瓶颈,因为 I/O 和 Redis 引擎共享一个 vCPU。因此,多 vCPU 配置的好处将无法实现。Memorystore for Redis 为所有运行版本 6 的实例启用了 I/O 多线程,允许使用多个 vCPU 同时处理 I/O 并提高实例吞吐量。请记住,由于多线程,CPU 秒数指标可能会突然超过 1 秒,这表明利用率超过 100%,因为它是一个聚合指标。
Memorystore for Redis 提供不同的容量层。容量层大小决定了 Redis 6 的单节点性能和 I/O 线程数。
下表描述了与 Redis 版本相关的不同容量层和每个层的 I/O 线程。Redis 6 的多线程需要 M3 容量层和更高层。
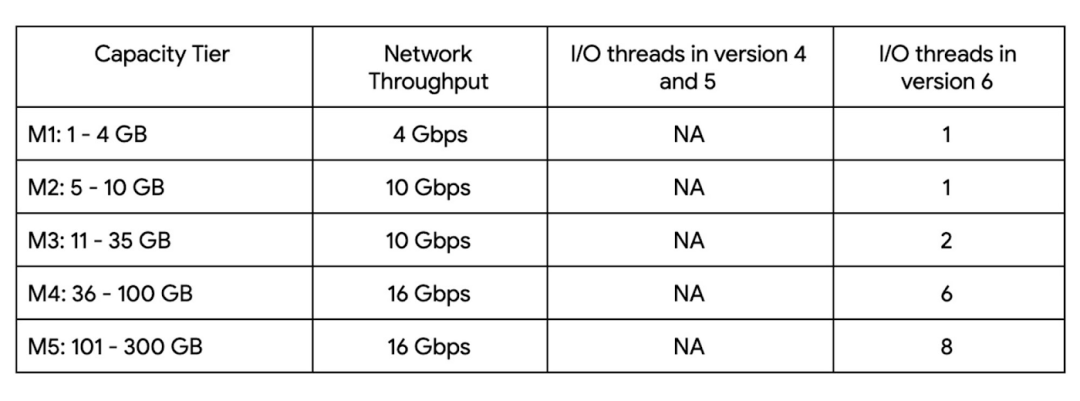
注意:使用 Redis 6 多线程时,可能会观察到 CPU 利用率突然超过 100%。这表明该实例正在使用多个核心。例如,对于具有 6 个线程的 M4 实例,CPU 利用率可能会飙升至 600%,表明所有 6 个内核的利用率。
最佳实践:
谷歌建议使用 Redis 6 部署所有新创建的实例,以利用多线程的优势。如果性能和吞吐量对你的实例至关重要,谷歌建议部署 M3 层或更高层的实例。谷歌还建议升级现有的 Memorystore for Redis 实例。它通常是微不足道且安全的,因为 Redis 旨在使 API 向后兼容,但谷歌始终建议在尝试进行任何升级之前进行适当的测试。
除了 Redis 6 的多线程之外,你还可以通过向实例添加只读副本来显著提高性能。每个额外的只读副本线性扩展总读取吞吐量,最多支持 5 个只读副本。
配置维护窗口以实现平稳运行
Memorystore 会自动更新你的实例。这些更新对于维护实例的安全性、性能和高可用性至关重要,并且是它作为完全托管服务的众多优势之一。
Memorystore for Redis 让你能够定义维护窗口,即一周中特定日期的 1 小时时段,在此期间应执行维护。配置维护窗口可让你预测何时可能进行维护。如果没有为实例配置维护窗口,则可以在任何时间和任何一天进行维护。这意味着可能会在应用程序的高峰使用时间进行维护。
最佳实践:
谷歌建议将以下内容作为 Memorystore for Redis 维护窗口的最佳实践,以减少和最小化维护的影响并获得最佳的维护体验:
你应该为你的实例设置一个维护窗口,这样维护就不会发生在高峰活动期间,而只会发生在低使用时间(例如:周日早上)。
你应该选择加入维护通知,以便在为你的实例安排维护更新前至少 7 天通过电子邮件收到提醒。
确保系统内存使用率指标在维护开始时低于 50%。你可以通过安排实例流量较低的时间或通过在维护窗口期间临时扩大实例大小来实现此目的。
考虑影响最低的标准层级。维护期间基本层实例不可用,最多可能持续 5 分钟。
在缓存数据至关重要时配置 Memorystore 高可用性
Memorystore 有两个层级,基本层和标准层。基本层由具有临时缓存且无复制的单个节点组成。由于没有备份或复制,基本层故障可能会导致缓存日期丢失。标准层通过复制提供高可用性 (HA) 和 99.9% 可用性 SLA,如果主节点出现故障,将自动故障转移到副本。此 HA 功能将为你的应用程序提供对关键缓存数据的更可靠和一致的访问,即使在发生故障时也是如此。该实例将暂时不可用几秒钟,同时发生故障转移并建立与现在已变为主实例的副本的连接。
Memorystore for Redis 标准层可以有多达五个只读副本以实现高可用性和扩展。默认情况下不启用只读副本。启用后,除了提供高可用性外,它们还允许你扩展读取工作负载并提供单个读取端点,将查询分布到所有副本节点。
最佳实践:
对于不能容忍完全缓存刷新的应用程序,标准层是推荐的部署层。通过利用 RDB 快照可以实现额外的数据持久性。
避免这些 Redis 命令和反模式
避免这些 Redis 命令和反模式以获得实例的最佳性能和安全性并优化成本。
使用 KEYS 命令 - 在大型数据库上使用时,使用 KEYS 命令可能会显著影响实例的性能。
最佳做法是谨慎行事,避免在生产环境中使用 KEYS 命令。使用 KEYS 命令的替代方法是使用 SCAN 命令。
避免返回无限结果的命令 - 某些命令(如 LRANGE、HGETALL、ZRANGE)可以返回非常大量的键和数据,这会对服务器的性能产生不利影响。
最佳做法是使用支持命令检查数据结构的大小,以确保大小不会太大
Redis 作为没有高可用性或 RDB 快照的持久层 - 如果没有配置高可用性或定期计划的 RDB 快照,Memorystore Redis 数据将在实例失败时丢失。
最佳做法是将高可用性与标准层和 RDB 快照一起用于关键数据,或者在应用程序依赖于 Memorystore for Redis 中某种程度的持久性的情况下。
在客户端连接逻辑中实现指数退避
指数退避是一种标准的错误处理策略。它通过以增加但随机的延迟重试失败的请求来工作。这有助于缓解由于用户点击刷新或传入请求大量积压导致延迟暂时增加导致大量请求的情况。
随机化是重试策略的关键组成部分。每次重试都会增加时间,但也需要有一些随机变化,这样就不会出现大波同时重试。随机变化的范围通常在 1-1000 毫秒之间。
重试策略应包括最大退避,以便重试不会等待超过 32 或 64 秒并最终失败,因此重试不是无限的。
最佳实践:
最佳实践是开发具有稍微随机但增加退避的重试逻辑。它最终应该超时并通过警报机制通知应用程序团队。请注意,某些形式的这种形式可能已经在某些 redis 客户端中实现。
配置警报/监控
监控和警报是 Google Cloud 的重要功能。监控使谷歌能够随着时间的推移观察特定指标,以评估谷歌架构的健康状况。它们还有助于实时和历史地解决特定问题。警报可以根据你设置的阈值在出现问题时通知你。
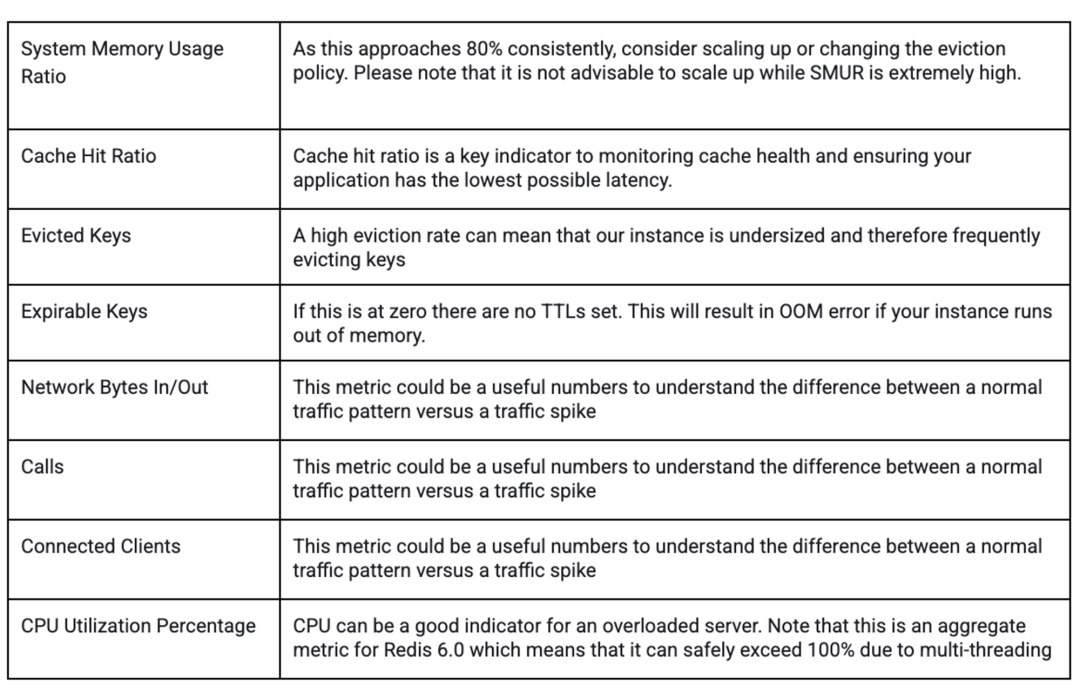
谷歌建议为以下一些关键指标设置警报,例如 SMUR 和正常运行时间。这些应该由你的应用程序模式定制,以捕获问题但最大限度地减少错误警报。
要监控的常用指标
———
WebEye是中国大陆地区首家获得 Google Cloud MSP 资质的合作伙伴。WebEye致力于用创新的技术向中国企业提供数字化效率创新服务,实现数字化赋能。我们不断帮助客户打造新的运营与协作方式,打造新的竞争优势,构建资源高效链接,共创价值生长空间。
WebEye整合全球资源,打造全球数字化营销体系,为企业提供营销增长服务、营销增长引擎以及企业上云三大板块业务,涵盖数字营销、数字创意、游戏发行、流量变现、程序化广告、数据洞察、云计算等一站式全链条增长产品矩阵,是中国互联网出海领军企业。