数据对于任何应用程序都是必不可少的,并且用于设计有效的管道以在整个组织中交付和管理信息。当你需要在其生命周期内处理数据时,通常定义数据管道。管道可以从生成数据并以任何格式存储的地方开始。管道可以以数据被分析、用作业务信息、存储在数据仓库中或在机器学习模型中处理结束。
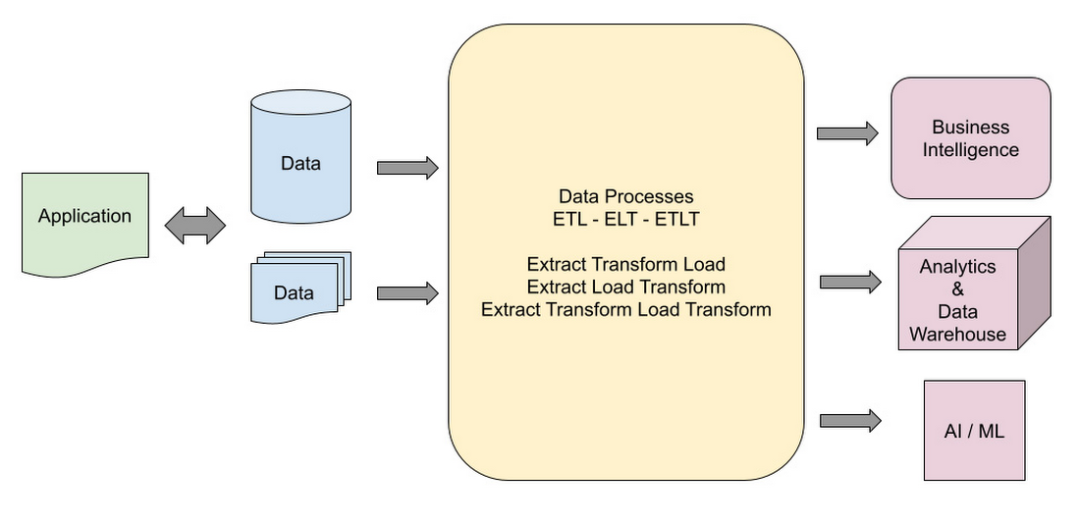
根据下游系统要求,数据在多个步骤中被提取、处理和转换。任何处理和转换步骤都在数据管道中定义。根据要求,管道可以像一个步骤一样简单,也可以像多个转换和处理步骤一样复杂。
如何选择设计模式
选择数据管道设计模式时,必须考虑不同的设计元素。这些设计元素包括以下内容:
选择数据源格式。
选择要使用的堆栈。
选择数据转换工具。
在提取转换负载 (ETL)、提取负载转换 (ELT) 或提取转换负载转换 (ETLT) 之间进行选择。
确定如何管理更改的数据。
确定如何捕获更改。
数据源可以有多种数据类型。了解我们使用的技术堆栈和工具集也是管道构建过程的关键要素。企业环境带来的挑战需要使用多种复杂的技术来捕获更改的数据并与目标数据合并。
大多数时候下游系统定义了管道的要求以及这些流程如何相互连接。数据流的处理步骤和顺序是影响流水线设计的主要因素。每个步骤可能包括一个或多个数据输入,而输出可能包括一个或多个阶段。输入和输出之间的处理可能包括简单或复杂的转换步骤。谷歌建议保持设计简单和模块化,以确保你清楚地了解发生的步骤和转换。此外,保持管道设计简单和模块化可以让开发团队更轻松地实施开发和部署周期。它还可以在出现问题时更轻松地调试和排除管道故障。
管道的主要组成部分包括:
源数据
加工
目标存储
源数据可以是交易应用程序、从用户那里收集的文件以及从外部 API 提取的数据。源数据的处理可以像一步复制一样简单,也可以像多次转换和与其他数据源连接一样复杂。目标数据仓库系统可能需要作为转换(例如数据类型更改或数据提取)结果的已处理数据,以及来自其他系统的查找和更新。可以通过将数据从源复制到目标而不进行任何更改来创建一个简单的数据管道。出于不同原因,复杂的数据管道可能包括多个转换步骤、查找、更新、KPI 计算和数据存储到多个目标。

源数据可以多种格式呈现。每个都需要适当的架构和工具来处理和转换。典型数据管道中可能需要多种数据类型,这些数据类型可能采用以下任何一种格式:
批处理数据:包含表格信息(CSV、JSON、AVRO、PARQUET 等)的文件,其中数据是根据定义的阈值或频率使用传统批处理或微批处理收集的。现代应用程序倾向于生成连续数据。出于这个原因,微批处理是从源收集数据的首选设计。
事务数据:应用程序数据,例如 RDBMS(关系数据)、NoSQL、大数据。
流数据:使用 Kafka、Google Pub/Sub、Azure 流分析或 Amazon 流数据的实时应用程序。流式数据应用可以实时通信和交换消息来满足要求。在企业架构设计中,实时和流处理是设计中非常重要的组成部分。
平面文件 - 包含待处理数据的 PDF 或其他非表格格式。例如,可用于提取信息的医疗或法律文件。
目标数据是根据要求和下游处理需要定义的。构建目标数据以满足多个系统的需要是很常见的。在数据湖概念中,数据的处理和存储方式使分析系统能够获得洞察力,而 AI/ML 过程可以使用数据构建预测模型。
架构和示例
数据管道架构可以分为逻辑和平台级别。逻辑设计描述了如何处理数据并将其从源转换为目标。平台设计侧重于每个环境所需的实现和工具,这取决于平台中可用的提供商和工具。Google Cloud、Azure 或 Amazon 具有不同的转换工具集,但无论使用哪个提供商,逻辑设计的目标都保持不变(数据转换)。
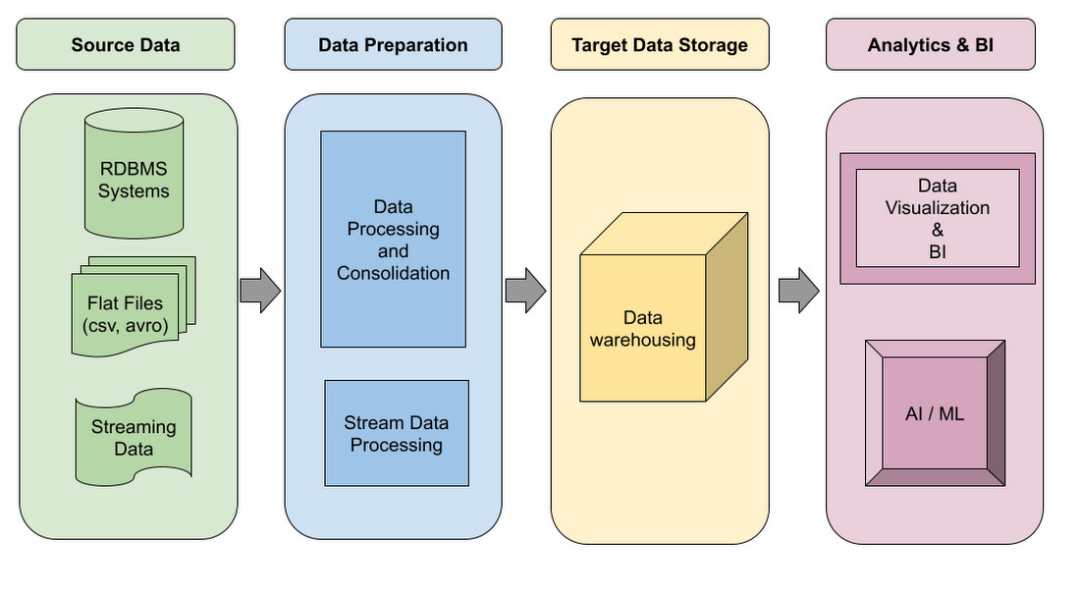
这是数据仓库管道的逻辑设计:
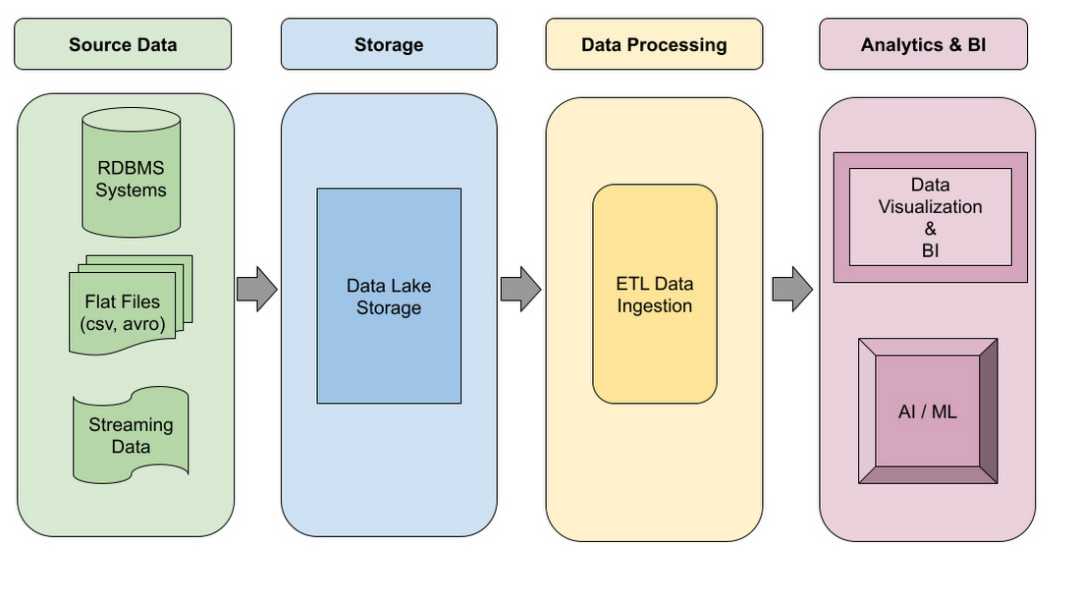
以下是数据湖管道的逻辑设计:
根据下游需求,可以使用更多细节来实现通用架构设计,以解决多个用例。
平台实施可能因工具集选择和开发技能而异。以下是常见数据管道架构的 Google Cloud 实现的几个示例。
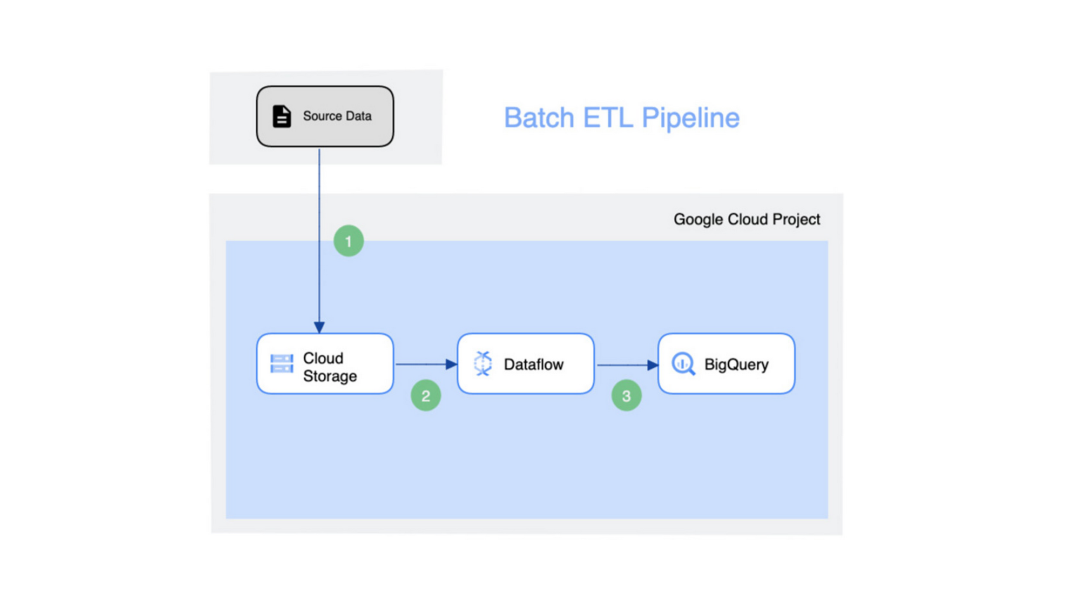
Google Cloud 中的批量 ETL 管道 - 源可能是需要引入分析商业智能 (BI) 引擎的文件。Cloud Storage是 Google Cloud 内部的数据传输介质,然后使用Dataflow 将数据加载到目标 BigQuery 存储中。这种方法的简单性使得这种模式在简单的转换过程中可重用和有效。但如果需要构建一个复杂的管道,那么这种方法将不再奏效。
Data Analytics Pipeline 是一个复杂的过程,具有批处理和流数据摄取管道。处理过程很复杂,需要使用多种工具和服务将数据转换为仓库和 AL/ML 访问点以进行进一步处理。用于数据分析的企业解决方案很复杂,需要多个步骤来处理数据。设计的复杂性会增加项目时间和成本,但为了实现业务目标,请仔细审查和构建每个组件。
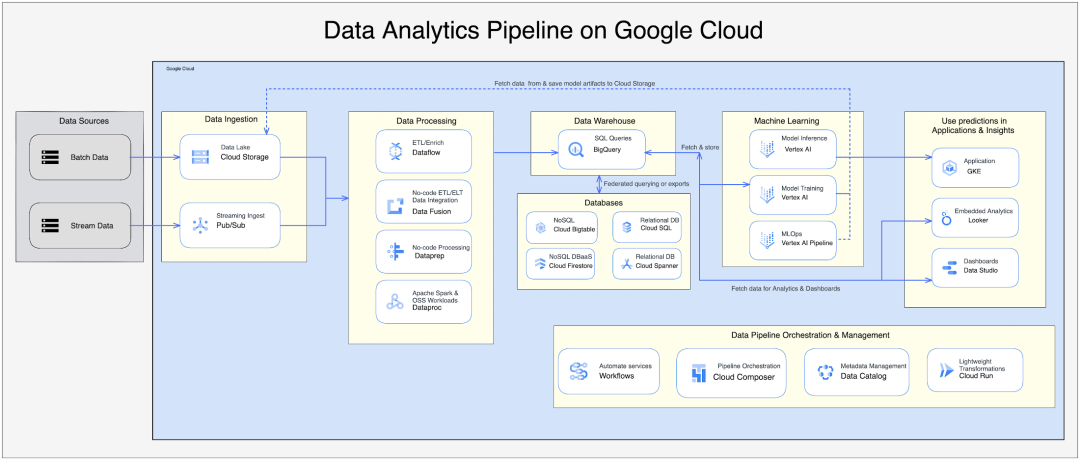
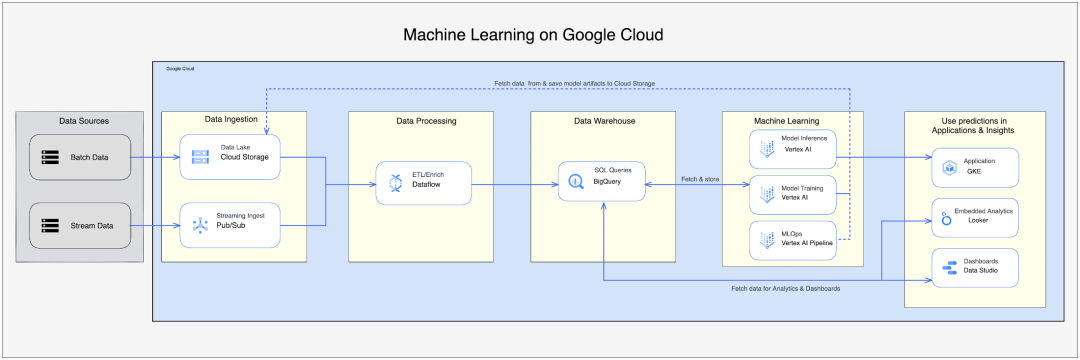
Google Cloud 中的机器学习数据管道是一种综合设计,允许客户利用所有 Google Cloud 原生服务来构建和处理机器学习流程。
如何选择数据流水线架构
设计和实现数据管道有多种方法。关键是要选择符合你要求的设计。新兴技术正在为数据管道提供更强大和更快的实现。Google Big Lake 是一项新服务,引入了一种新的数据摄取方法。BigLake 是一种存储引擎,它通过启用 BigQuery 和开源框架(例如 Spark)以细粒度访问控制访问数据来统一数据仓库。BigLake 提供跨多云存储和开放格式(如 Apache Iceberg)的加速查询性能。
设计数据管道时不要忽略数据量。平台中使用的设计和服务的可扩展性是设计和实施解决方案时需要考虑的另一个非常重要的因素。大数据正在不断增长,并正在建设处理能力。存储数据是数据管道架构的关键要素。实际上,有许多变量可以帮助进行适当的平台设计。数据量和速度或数据流率可能是非常重要的因素。
如果你计划为数据科学项目构建数据管道,那么你可能会考虑 ML 模型在未来工程中所需的所有数据源。数据清理过程主要是数据工程团队的重要组成部分,该团队必须拥有足够的转换工具集。数据科学项目正在处理大型数据集,这需要规划存储。根据 ML 模型的使用方式,实时或批处理必须为用户服务。
决定合适的数据管道架构的另一个主要因素是成本。构建具有成本效益的解决方案是决定设计的主要因素。通常,与使用批处理模型相比,流式和实时数据处理管道的构建和运行成本更高。有时预算会决定选择哪种设计以及如何构建平台。了解每个组件的详细信息并能够提前对解决方案进行成本分析对于为你的解决方案选择正确的架构设计非常重要。Google Cloud 提供了一个成本计算器,可用于这些情况。
你真的需要实时分析,还是一个接近实时的系统就足够了?这可以解决流式管道的设计决策。你是在构建云原生解决方案还是从本地迁移现有解决方案?所有这些问题对于为数据管道设计合适的架构都很重要。
———
WebEye是中国大陆地区首家获得 Google Cloud MSP 资质的合作伙伴。WebEye致力于用创新的技术向中国企业提供数字化效率创新服务,实现数字化赋能。我们不断帮助客户打造新的运营与协作方式,打造新的竞争优势,构建资源高效链接,共创价值生长空间。
WebEye整合全球资源,打造全球数字化营销体系,为企业提供营销增长服务、营销增长引擎以及企业上云三大板块业务,涵盖数字营销、数字创意、游戏发行、流量变现、程序化广告、数据洞察、云计算等一站式全链条增长产品矩阵,是中国互联网出海领军企业。