自推出以来,企业一直在使用 BigQuery 来满足他们的数据仓库需求。许多这些企业经常将非常大的数据集加载到他们的企业数据仓库中。无论是使用数百 TB 的数据进行初始数据摄取,还是从记录系统进行增量加载,批量插入的性能都是更快地从数据中获得洞察力的关键。批量数据加载最常见的架构使用谷歌云存储(对象存储)作为所有批量加载的暂存区。所有不同的文件格式都在 BigQuery 中转换为优化的列格式,称为“Capacitor”。该文章将重点关注各种文件类型以获得最佳性能。上传到 BigQuery 的数据文件通常采用逗号分隔值 (CSV)、AVRO、PARQUET、JSON、ORC 格式。我们将使用两个大型数据集来比较和对比这些文件格式中的每一种。我们还将探讨每种文件格式的压缩数据与未压缩数据的加载效率。可以使用 GCP 生态系统中的多种工具将数据加载到 BigQuery 中。你可以使用 Google Cloud 控制台、bq load 命令、使用 BigQuery API 或使用客户端库。本文将阐明把批量数据加载到 BigQuery 的各种选项,并提供有关每种文件类型和加载机制的性能数据。将数据加载到 BigQuery 时,你需要考虑多种因素。
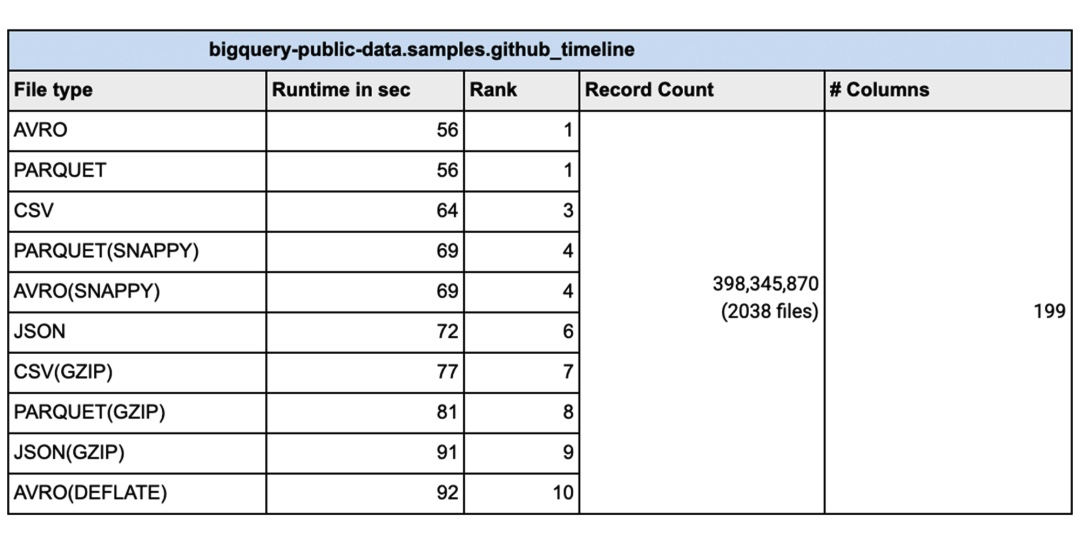
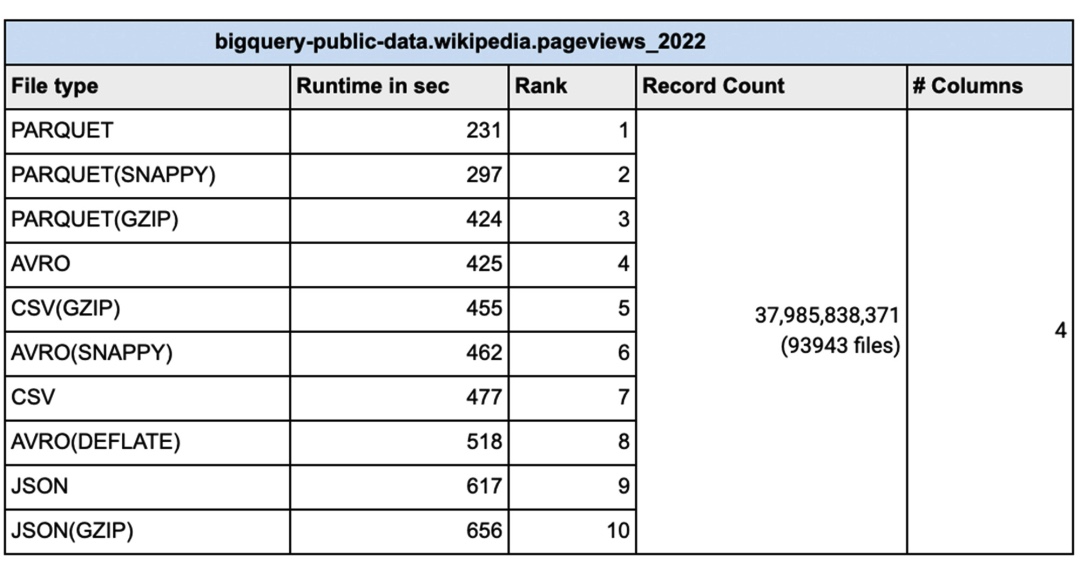
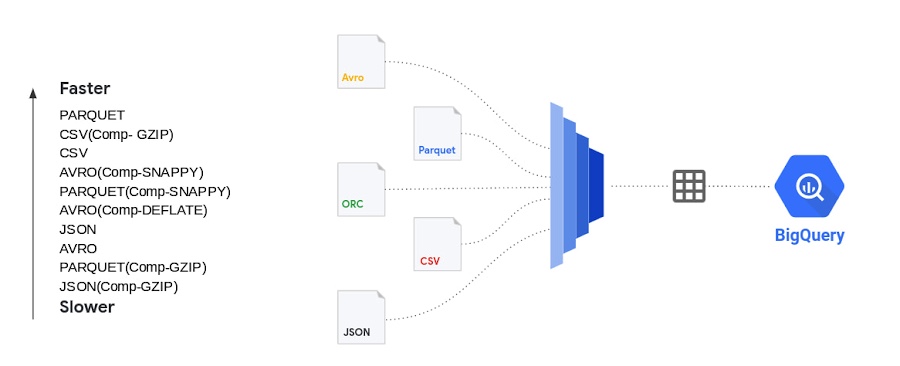
批量插入 BigQuery 是插入数据的最快方式,可提高速度和成本效益。然而,当你需要立即报告数据时,流式插入会更有效。今天的数据文件有许多不同的文件类型,包括逗号分隔 (CSV)、JSON、PARQUET、AVRO 等等。我们经常被问及文件格式的重要性以及选择一种文件格式是否比另一种文件格式有任何优势。CSV 文件(逗号分隔值)包含带有标题行命名列的表格数据。加载数据时,可以解析列名的标题。从 CSV 文件加载时,可以使用模式自动检测的标题行来选取列。模式自动检测设置为关闭时,可以跳过标题行并使用标题中的列名手动创建模式。CSV 文件也可以使用其他字段分隔符(如 ; 或 |)作为分隔符,因为许多数据输出的数据中已经有逗号。不能以 CSV 文件格式存储嵌套或重复的数据。JSON(JavaScript 对象表示法)数据以半结构化格式存储为键值对。JSON 是首选的文件类型,因为它可以以分层格式存储数据。JSON 数据行的无模式特性提供了发展模式的灵活性,从而改变了负载。JSON 格式是用户可读的。基于 REST 的 Web 服务使用 json 而不是其他文件类型。PARQUET 是一种面向列的数据文件格式,旨在高效地存储和检索数据。PARQUET 压缩和编码非常高效,并提供改进的性能来批量处理复杂数据。AVRO:数据以二进制格式存储,模式以 JSON 格式存储。这有助于最小化文件大小并最大化效率。从数据加载的角度来看,谷歌对具有从窄到宽列数据的数百万到数千亿行进行了各种测试并使用名为“bigquery-public-data.samples.github_timeline”和“bigquery-public”的公共数据集完成了此测试-data.wikipedia.pageviews_2022`。谷歌使用 1000 个 flex 插槽进行测试,加载(称为 PIPELINE 插槽)插槽的数量限制为你为你的环境分配的插槽数量。架构自动检测设置为“否”。对于数据文件的并行化,每个未压缩的文件通常应小于 256MB 以实现更快的吞吐量。有时会压缩批处理文件,以便更快地通过网络传输到云端。特别是对于正在传输的大数据文件,在通过云互连或 VPN 连接发送之前压缩数据会更快。在这种情况下,在加载到 BigQuery 之前解压缩数据会更好吗?以下是谷歌使用不同压缩算法对具有不同文件大小的各种文件类型进行的测试。显示的结果是五次运行的平均值:可以通过多种方式将数据加载到 BigQuery 中。你可以使用 Google Cloud Console、命令行、客户端库或使用REST API。由于所有这些负载类型在后台调用相同的 API,因此选择一种方式比另一种方式没有优势。谷歌使用了1000条管道插槽保留,用于执行上面显示的数据加载。对于需要可预测加载时间的工作负载,必须使用 PIPELINE 插槽预留,以便加载作业不依赖于默认池中可用插槽的变化无常。在现实世界中,谷歌的许多客户同时进行多个加载作业。在这些情况下,必须小心地将 PIPELINE 插槽分配给各个作业,以在加载时间和插槽效率之间保持平衡。结论:对于谷歌所做的测试,当源文件为压缩格式时,加载时间没有明显优势。事实上,大部分未压缩数据的加载时间与压缩数据相同或更快。对于包括 AVRO、PARQUET 和 JSON 在内的所有文件类型,压缩文件后加载数据的时间会更长。减压是一项 CPU 密集型活动,你的里程根据分配给你的加载作业的 PIPELINE 插槽数量而有所不同。数据加载槽(PIPELINE槽)不同于数据查询槽。对于压缩文件,你应该并行加载操作,以确保数据加载高效。将数据文件拆分为 256MB 或更小以加速数据加载的并行化。从性能的角度来看,AVRO 和 PARQUET 文件具有相似的加载时间。修复你的架构确实比架构自动检测设置为“ON”更快地加载数据。关于 ETL 作业,使用 SQL 在 BigQuery 内部进行转换更快更简单,但如果你有复杂的转换需求而 SQL 无法完成,请使用 Dataflow 进行统一批处理和流式处理,使用 Dataproc 进行基于流式处理的管道,或 Cloud Data Fusion 用于无代码/低代码转换需求并尽可能避免隐式/显式数据类型转换以加快加载时间。
———
WebEye是中国大陆地区首家获得 Google Cloud MSP 资质的合作伙伴。WebEye致力于用创新的技术向中国企业提供数字化效率创新服务,实现数字化赋能。我们不断帮助客户打造新的运营与协作方式,打造新的竞争优势,构建资源高效链接,共创价值生长空间。
WebEye整合全球资源,打造全球数字化营销体系,为企业提供营销增长服务、营销增长引擎以及企业上云三大板块业务,涵盖数字营销、数字创意、游戏发行、流量变现、程序化广告、数据洞察、云计算等一站式全链条增长产品矩阵,是中国互联网出海领军企业。