GCP 提供了一系列用于构建Data Pipeline的技术。首先从Cloud Dataflow 开始,这是一个基于 Apache Beam 的产品,它充分利用 GCP 的可管理性和可扩展性来提供大数据处理能力。其次是Cloud Pub/Sub,它是一个托管消息队列,类似于 Kafka 和 Amazon Kinesis。所有这些技术都提供了与 GCP 上可用的各种数据源和接收器的原生集成,包括 Cloud Storage、Cloud Bigtable 或 BigQuery。这些pipeline可以连接到下游分析任务中,以创建端到端数据流。
Cloud Dataflow
Dataflow是用于执行各种数据处理任务的托管服务。它源自Apache Beam。
Apache Beam是一种开源编程模型,使开发者能够开发批处理和流式数据管道。开发者使用 Apache Beam 程序创建管道,然后在 Dataflow 服务上运行它们。
Cloud Pub/Sub
Pub/Sub 用于流式分析和数据集成管道以采集和分发数据。
发布者将数据事件发送到 Pub/Sub 服务,而不考虑如何或何时处理这些事件。然后,Pub/Sub 将事件传递给需要对其做出反应的所有服务。与通过 RPC 进行通信的系统(发布者必须等待订阅者接收数据)相比,这种异步集成提高了整个系统的灵活性和健壮性。
Cloud Storage
Cloud Storage 是一项用于将您的对象存储在 Google Cloud 中的服务。对象是由任何格式的文件组成的不可变数据。您将对象存储在称为存储桶中。
动手实验
使用 Cloud Pub/Sub 和 Dataflow 进行流处理
实验中我们会做什么?
· 阅读发布到 Pub/Sub 主题的消息
· 按时间戳窗口(或分组)发送消息
· 将消息写入 Cloud Storage
1. 创建项目资源,开启API。
在 Cloud Shell 中,为您的存储桶、项目和区域创建变量
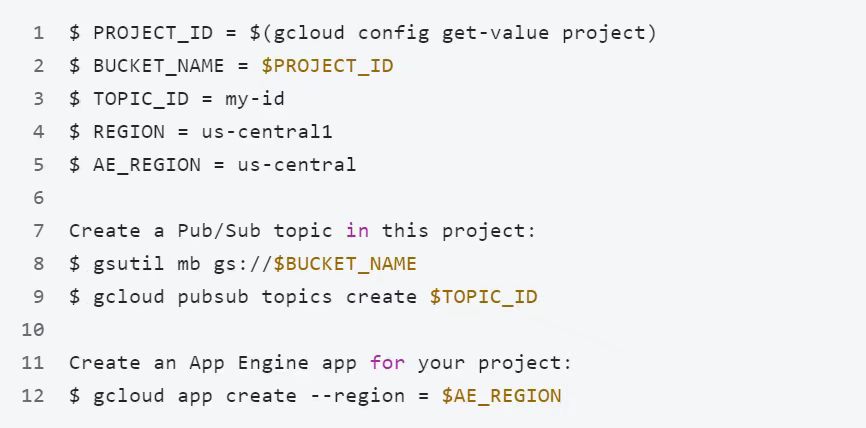
2. 启用Dataflow API和Pub/Sub API。
3. 在此项目中创建 Cloud Scheduler 作业。

该作业每隔一分钟向 Pub/Sub 主题发布一条消息。使用 Cloud Scheduler,您可以设置要在定义的时间或定期执行的工作单元。这些工作单元通常称为 cron 作业。典型的用例可能包括每天发送报告电子邮件、每 10 分钟更新一些缓存数据或每小时更新一些摘要信息。
4. 启动任务


5. 准备Dataflow运行环境,在cloud shell执行以下命令
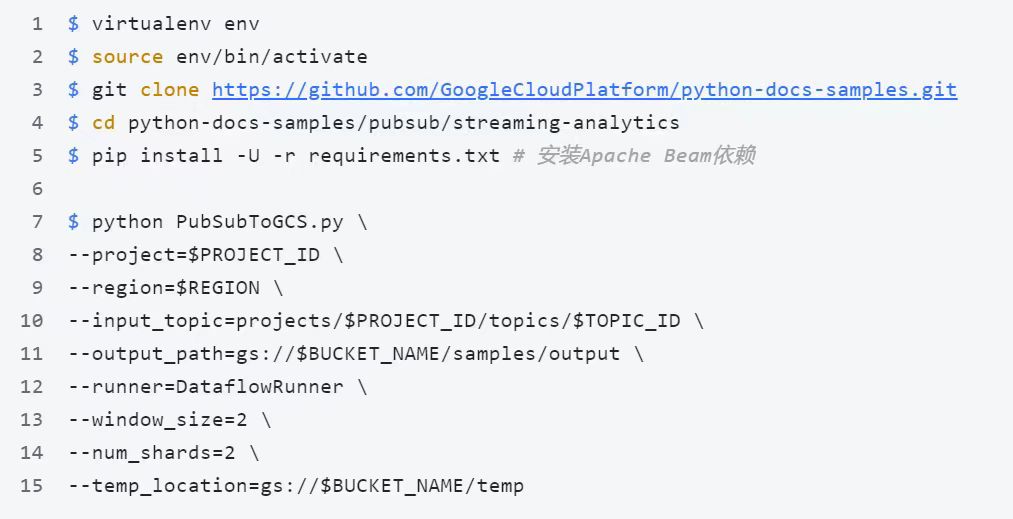
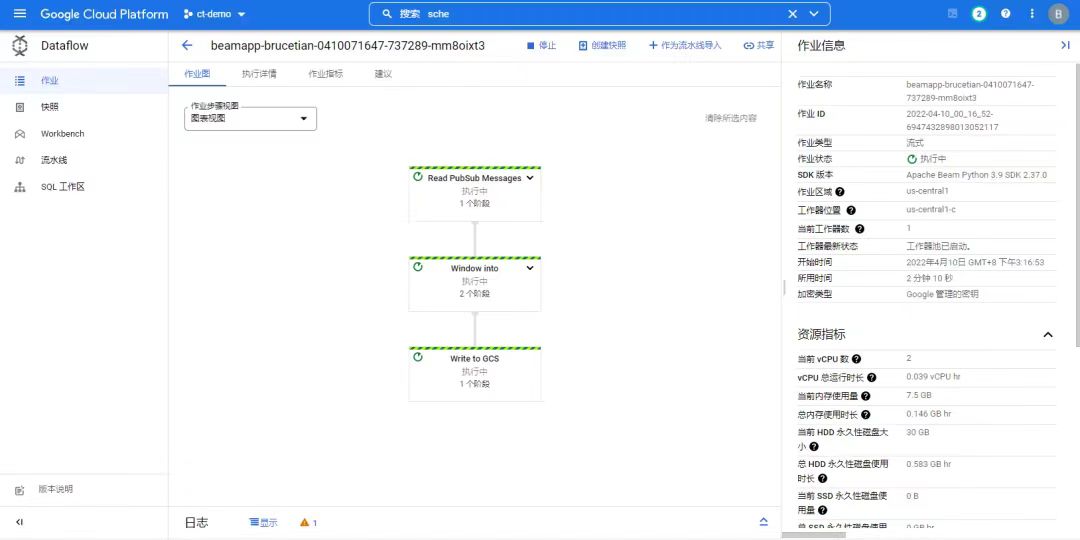
6. 执行成功后,可在Dataflow界面中看到运行的任务

7. 在存储桶中,我们可以看到实时生成的数据文件了!
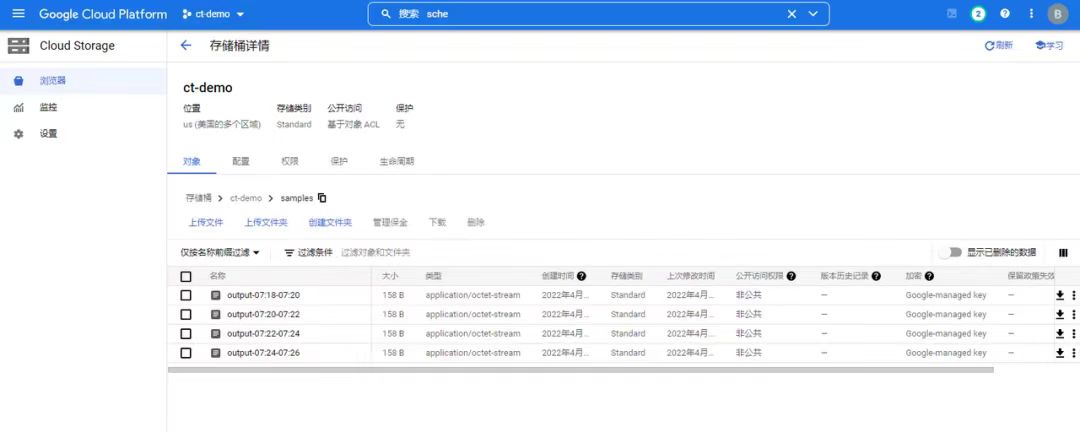
数据文件会定期更新,更新粒度在10分钟。
利用Cloud Pub/Sub和Dataflow,创建流式数据分析的实验就到这了!
WebEye是中国大陆地区首家获得 Google Cloud MSP 资质的合作伙伴。WebEye致力于用创新的技术向中国企业提供数字化效率创新服务,实现数字化赋能。我们不断帮助客户打造新的运营与协作方式,打造新的竞争优势,构建资源高效链接,共创价值生长空间。
WebEye整合全球资源,打造全球数字化营销体系,为企业提供营销增长服务、营销增长引擎以及企业上云三大板块业务,涵盖数字营销、数字创意、游戏发行、流量变现、程序化广告、数据洞察、云计算等一站式全链条增长产品矩阵,是中国互联网出海领军企业。