BigQuery BI Engine 是一种用于 BigQuery 的快速内存分析系统,目前每月处理超过 20 亿个查询,并且还在不断增长。BigQuery 起源于 Google 的 Dremel 系统,是以可扩展性为目标构建的数据仓库。另一方面,BI Engine 是为数据分析师设想的,专注于为实时分析和 BI 目的提供千兆字节到亚 TB 数据集的价值,只需最少的调整。
使用 BI 引擎很简单 - 在运行 BigQuery 查询的项目上创建内存预留,它将缓存数据并使用优化。这篇文章深入探讨了 BI 引擎如何帮助你为 BigQuery 查询提供超快的性能,以及用户可以做些什么来充分发挥其潜力。
BI 引擎优化
BI Engine 的两个主要支柱是数据的内存缓存和矢量化处理。其他优化包括CMETA 元数据修剪、单节点处理和较小表的连接优化。
矢量化引擎
BI Engine 使用“Superluminal”矢量化评估引擎,该引擎也用于 YouTube 的分析数据平台查询引擎 - Procella。在 BigQuery 的基于行的评估中,引擎将为每一行处理一行中的所有列。在转到下一行之前,引擎可能会在列类型和内存位置之间交替。相比之下,像 Superluminal 这样的矢量化引擎将尽可能长时间地处理来自单个列的相同类型的值块,并且只在必要时切换到下一列。这样,硬件可以使用 SIMD 同时运行多个操作,从而减少延迟和基础设施成本。BI 引擎动态选择块大小以适应缓存和可用内存。
对于示例查询,“SELECT AVG(word_count), MAX(word_count), MAX(corpus_date) FROM samples.shakespeare”,将具有以下矢量化计划。请注意评估如何将“word_count”与“corpus_date”分开处理。
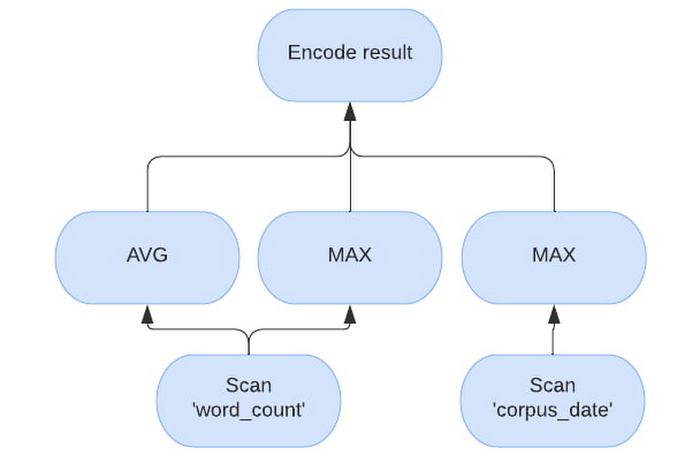
内存缓存
BigQuery 是一个分解的存储和计算引擎。通常 BigQuery 中的数据存储在 Google 的分布式文件系统 - Colossus中,通常以Capacitor格式的块形式存储,计算由Borg任务表示。这会启用 BigQuery 的缩放属性。为了充分利用矢量化处理,BI Engine 需要以 CPU 速度提供原始数据,这只有在数据已在内存中时才能实现。BI Engine 也运行 Borg 任务,但 worker 需要更多内存才能缓存从 Colossus 读取的数据。
单个 BigQuery 查询可以发送给单个 BI Engine worker,也可以分片并发送给多个 BI Engine worker。每个工作人员都会收到一段查询,并使用回答它所需的一组列和行来执行。如果上一个查询的数据没有缓存在 worker 内存中,则 worker 会将数据从 Colossus 加载到本地 RAM 中。仅从内存提供对相同列和行的相同或子集的后续请求。请注意,如果超过 24 小时未使用数据,工作人员将卸载内容。当多个查询到达时,有时它们可能需要比工作人员可用的更多 CPU 时间,如果仍有可用的预留,则新的工作人员将被分配到相同的块,并且对相同块的后续请求将在工作人员之间进行负载平衡。
BI 引擎还可以处理流式传输到 BigQuery 表的超新数据。因此,目前BI Engine worker支持的格式有两种——Capacitor和streaming。
内存中的电容器块
通常,电容器块中的数据在生成期间经过大量预处理和压缩。有许多不同的方法可以缓存来自电容器块的数据,一些方法的内存效率更高,而另一些方法的 CPU 效率更高。BI Engine worker 在可能的情况下在那些偏好延迟和 CPU 高效格式之间智能地进行选择。因此,由于缓存格式不同,实际预留内存使用量可能与逻辑或物理存储使用量不同。
内存中的流数据
流式数据作为原生数组列的块存储在内存中,并在底层存储进程将块提取到 Capacitor 中时延迟卸载。请注意,对于流式处理,BI 工作人员需要每次都转到流式存储以潜在地获取新块或提供稍微陈旧的数据。BI 引擎更喜欢提供稍微陈旧的数据并在后台加载新的流块。
BI Engine worker 在查询期间机会主义地执行此操作,如果 worker 检测到流数据并且缓存更新时间超过 1 分钟,则会在查询的同时启动后台刷新。实际上,这意味着如果有足够的请求,数据不会比之前的请求时间更陈旧。例如,如果每秒都有一个请求到达,那么流式数据将在一秒左右过时。
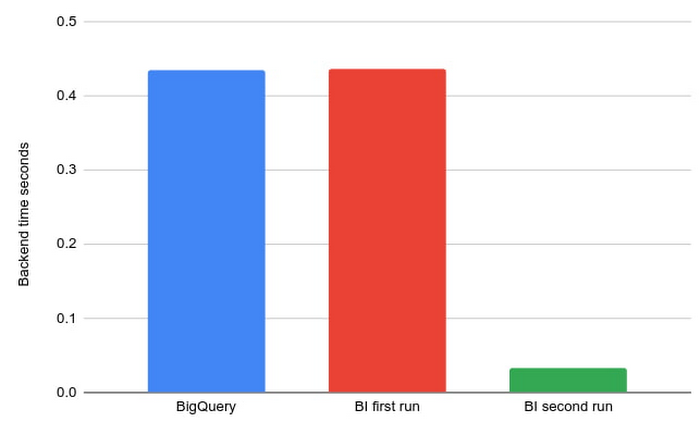
第一次请求加载数据很慢
由于读取时间优化,从以前看不见的列加载数据可能比 BigQuery 花费更长的时间。后续读取将受益于这些优化。
例如,此处上面的查询是在 BI 引擎关闭、首次运行和后续运行的情况下同一查询的示例运行的后端时间。
多块处理和动态单工执行
BI Engine worker 针对 BI 工作负载进行了优化,其中输出大小与输入大小相比较小,并且输出大部分会聚合。在常规 BigQuery 执行中,由于网络带宽限制,单个工作人员会尝试尽量减少数据加载。相反,BigQuery 依靠大规模并行来快速完成查询。另一方面,BI Engine 更喜欢在一台机器上并行处理更多的数据。如果数据已被缓存,则没有网络带宽限制,BI Engine 通过减少查询阶段之间的中间“洗牌”层数进一步降低网络利用率。
有了足够小的输入和一个简单的查询,整个查询将在一个 worker 上执行,查询计划将有一个用于整个处理的阶段。谷歌不断努力使更多的表和查询形状符合单阶段处理的条件,因为这是改善典型 BI 查询延迟的非常有前途的方法。
对于非常简单且表非常小的示例查询,这里是使用 BI Engine 分布式执行与单节点(默认)运行相同查询的示例。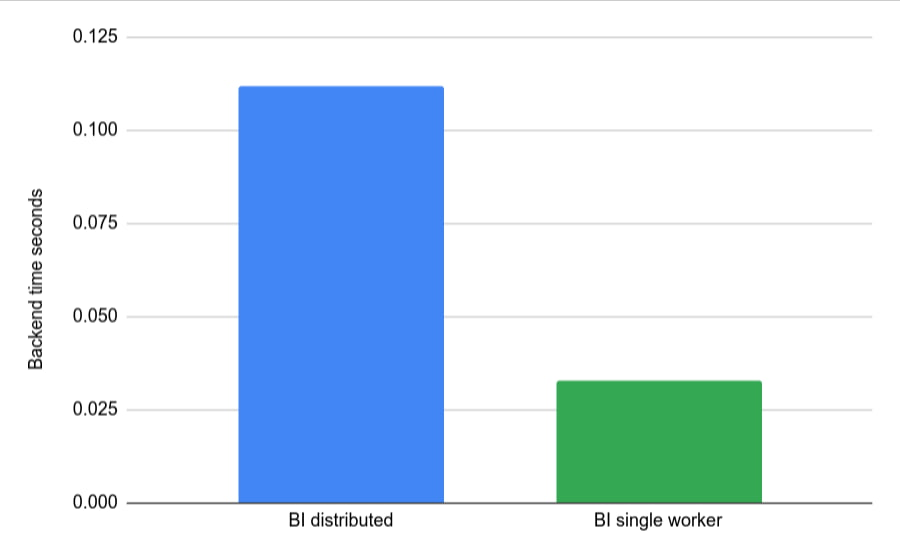
虽然我们都想要一个可以切换的开关并且一切都变得很快,但在使用 BI Engine 时仍然需要考虑一些最佳实践。
输出数据大小
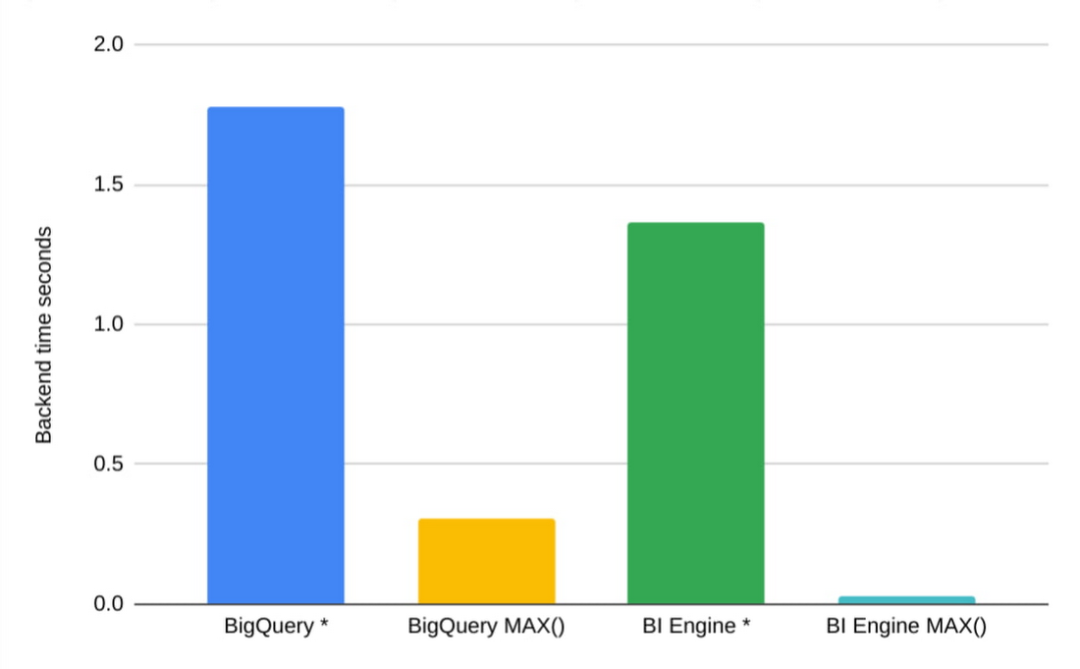
BI 优化假设人眼位于另一侧,并且输出数据的大小足够小,可以被人类理解。这种有限的输出大小是通过选择性过滤器和聚合实现的。作为必然结果,而不是 SELECT *(即使使用 LIMIT),更好的方法是为感兴趣的字段提供适当的过滤器和聚合。
为了在示例中展示这一点 - 查询“SELECT * FROM samples.shakespeare”处理大约 6MB 并在 BigQuery 和 BI Engine 中占用一秒钟。如果我们将 MAX 添加到每个字段 - “SELECT MAX(word), MAX(word_count), MAX(corpus), MAX(corpus_date) FROM samples.shakespeare”,两个引擎都会读取所有数据,执行一些简单的比较并完成在 BigQuery 上快 5 倍,在 BI Engine 上快 50 倍。
帮助 BigQuery 组织你的数据、
BI 引擎使用查询过滤器来缩小要读取的块集。因此,对数据进行分区和集群将减少要读取的数据量、延迟和插槽使用量。需要注意的是,“过度分区”或分区太多可能会干扰 BI 引擎多块处理。为了获得最佳的 BigQuery 和 BI Engine 性能,大于 1 GB 的分区是首选。
查询深度
BI 引擎目前加速了从表中读取数据的查询阶段,这些阶段通常是查询执行树的叶子。这在实践中意味着几乎每个查询都会使用一些 BigQuery 槽。这就是为什么当大量时间花在叶子阶段时,BI Engine 会获得最大的加速。为了缓解这种情况,BI 引擎尝试将尽可能多的计算推到第一阶段。理想情况下,在单个 worker 上执行它们,其中树只是一个节点。
比如TPCH 10G benchmark的Query1,比较简单。它分为 3 个阶段,具有高效的过滤器和聚合,可处理 3000 万行,但仅输出 1。
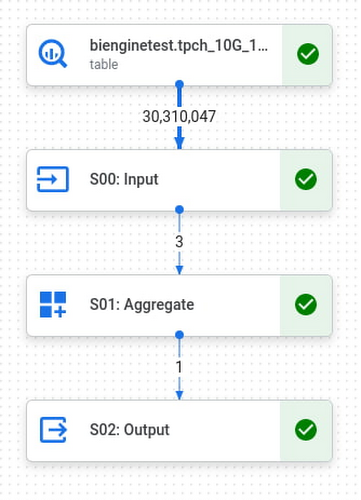
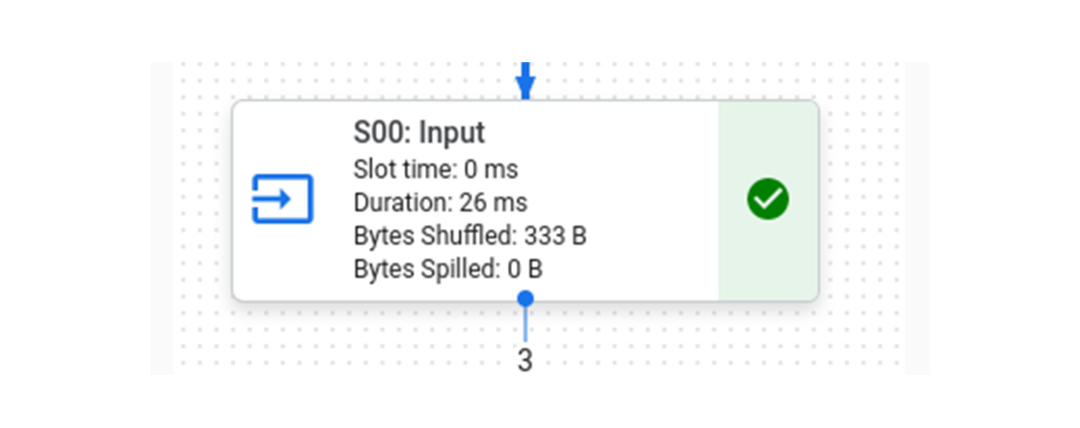
在 BI 引擎中运行这个查询,我们看到完整的查询花费了 215 毫秒,其中“S00:输入”阶段是 BI 引擎加速的阶段,花费了 26 毫秒。
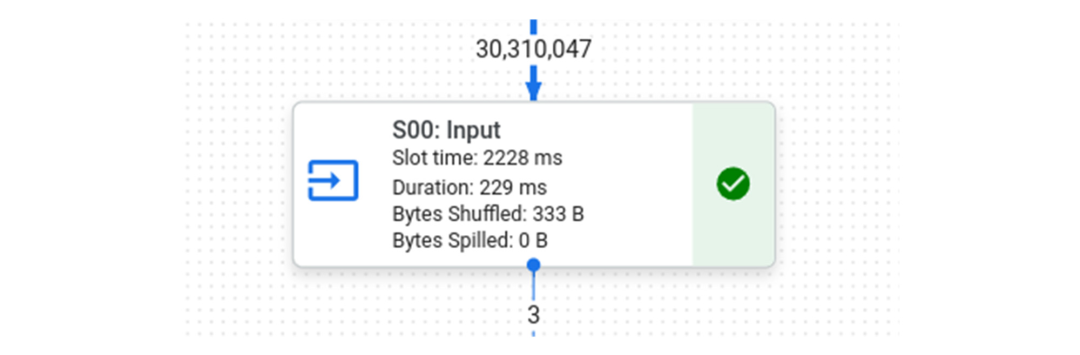
在 BigQuery 中运行相同的查询需要 583 毫秒,“S00:输入”需要 229 毫秒。
我们在这里看到的是“S00:输入”阶段的运行时间减少了 8 倍,但整体查询并没有快 8 倍,因为其他两个阶段没有加速,它们的运行时间大致保持不变。下图说明了阶段之间的细分。

在一个完美的世界中,BI 引擎在 0 毫秒内处理它的部分,查询仍然需要 189 毫秒才能完成。因此,此查询的最大速度增益约为 2-3 倍。
例如,如果我们通过运行 TPCH 100G 来使第一阶段的查询更重,我们会看到 BI Engine 完成查询的速度比 BigQuery 快 6 倍,而第一阶段快 30 倍!
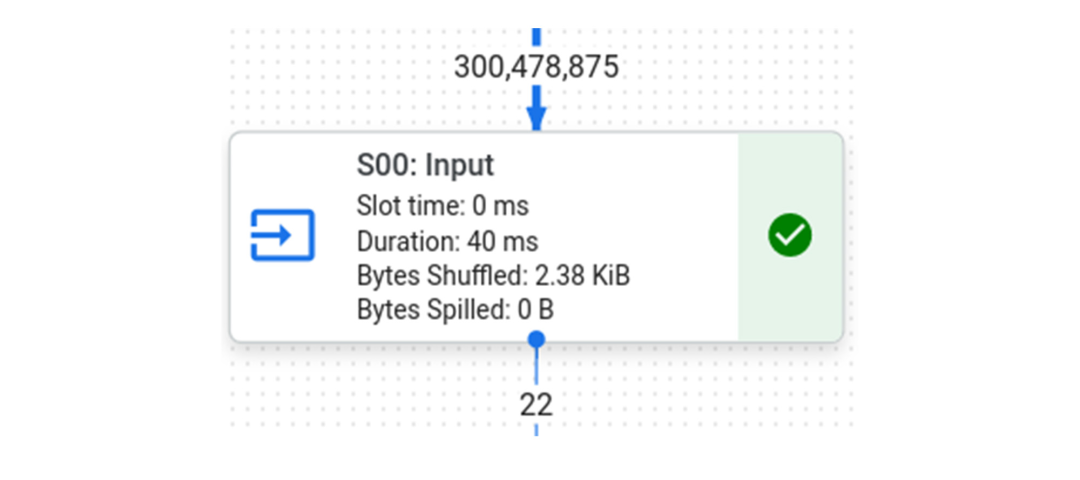
与 BigQuery 上的 1 秒相比

随着时间的推移,我们的目标是扩展符合条件的查询和数据形状,并将尽可能多的操作折叠到单个 BI 引擎阶段以实现最大收益。
加入
如前所述,BI 引擎加速了查询的“叶”阶段。但是,BI 引擎优化了一种在 BI 工具中使用的非常常见的模式。这是将一个大的“事实”表与一个或多个较小的“维度”表连接起来的时候。然后 BI 引擎可以执行多个连接,所有连接都在一个叶阶段,使用所谓的“广播”连接执行策略。
broadcast join时,事实表被分片在多个节点上并行执行,而维度表在每个节点上被完整读取。
例如,让我们从 TPC-DS 1G 基准测试运行查询 3。事实表是 store_sales,维度表是 date_dim 和 item。在 BigQuery 中,维表将首先加载到 shuffle 中,然后“S03:Join+”阶段将针对 store_sales 的每个并行部分,完整读取两个维表的所有必要列,以进行连接。
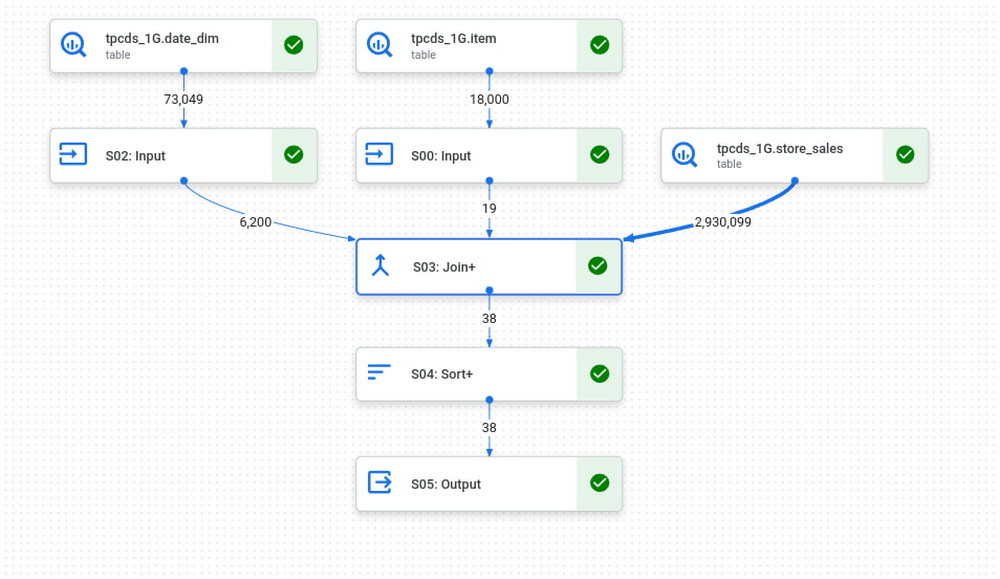
请注意,date_dim 和 item 上的过滤器非常有效,2.9M 行的事实表仅与大约 6000 行连接。BI Engine 的计划看起来会有点不同,因为 BI Engine 会直接缓存维度表,但原理是一样的。
对于 BI Engine,我们假设由于 store_sales 表对于单个节点处理来说太大,因此两个节点将处理查询。我们可以在下图中看到两个节点将具有相似的操作 - 读取数据、过滤、构建查找表然后执行连接。虽然每个表仅处理 store_sales 表的数据子集,但重复维度表上的所有操作。
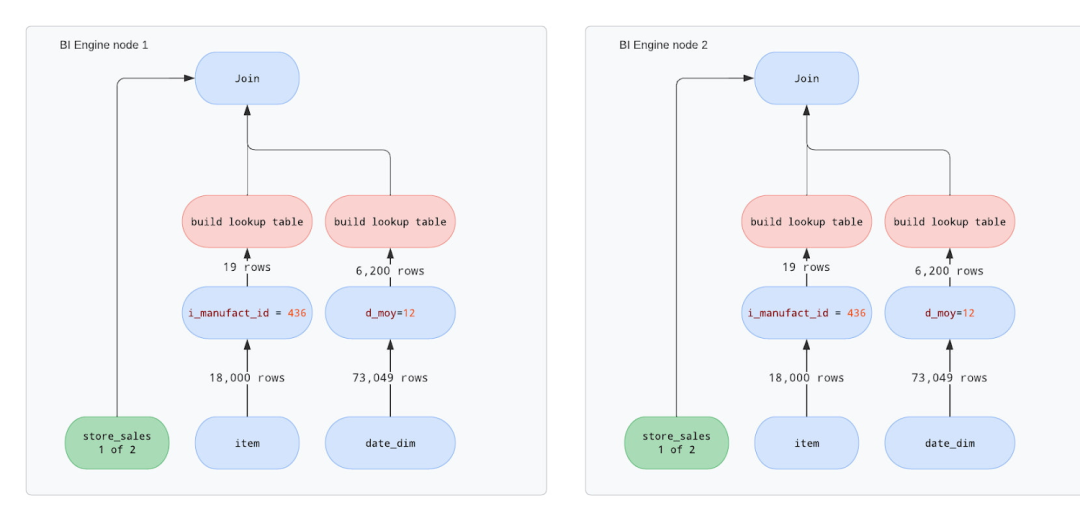
注意
与过滤相比,“构建查找表”操作非常占用 CPU
如果查找表很大,“join”操作性能也会受到影响,因为它会干扰 CPU 缓存局部性
维度表需要复制到事实表的每个“块”
要点是,当 BI Engine 执行连接时,事实表有时会拆分为不同的节点。所有其他表将在每个节点上复制多次以执行连接。保持维度表较小或有选择性的过滤器将有助于确保连接性能最佳。
结论
总结以上所有内容,可以做一些事情来充分利用 BI 引擎并加快查询速度
当涉及到返回的数据时,少即是多——确保在查询的早期过滤和聚合尽可能多的数据。将过滤器和计算下推到 BI 引擎中。
具有少量阶段的查询获得最佳加速。预处理数据以最小化查询复杂性将有助于获得最佳性能。例如,使用物化视图可能是一个不错的选择。
连接有时很昂贵,但 BI Engine 在优化典型的星型模式查询方面可能非常有效。
对表进行分区和/或集群以限制要读取的数据量是有益的。